




IC-Chips für integrierte Schaltkreise an einem Ort kaufen EPM240T100C5N IC CPLD 192MC 4.7NS 100TQFP


Produkteigenschaften
| TYP | BESCHREIBUNG |
| Kategorie | Integrierte Schaltkreise (ICs) Eingebettet CPLDs (Komplexe programmierbare Logikgeräte) |
| Hersteller | Intel |
| Serie | MAX® II |
| Paket | Tablett |
| Standardpaket | 90 |
| Produktstatus | Aktiv |
| Programmierbarer Typ | Im System programmierbar |
| Verzögerungszeit tpd(1) Max | 4,7 ns |
| Spannungsversorgung – Intern | 2,5 V, 3,3 V |
| Anzahl der Logikelemente/Blöcke | 240 |
| Anzahl der Makrozellen | 192 |
| Anzahl der E/A | 80 |
| Betriebstemperatur | 0°C ~ 85°C (TJ) |
| Befestigungsart | Oberflächenmontage |
| Paket/Koffer | 100-TQFP |
| Gerätepaket des Lieferanten | 100-TQFP (14×14) |
| Basisproduktnummer | EPM240 |
Die Kosten waren eines der Hauptprobleme bei 3D-verpackten Chips, und Foveros wird dank seiner führenden Verpackungstechnologie das erste Mal sein, dass Intel sie in großen Stückzahlen produziert.Intel sagt jedoch, dass Chips, die in 3D-Foveros-Gehäusen hergestellt werden, im Vergleich zu Standard-Chipdesigns äußerst preislich konkurrenzfähig sind – und in einigen Fällen sogar billiger sein können.
Intel hat den Foveros-Chip so konzipiert, dass er möglichst kostengünstig ist und dennoch die erklärten Leistungsziele des Unternehmens erfüllt – es ist der günstigste Chip im Meteor-Lake-Paket.Intel hat die Geschwindigkeit der Foveros-Verbindungs-/Basiskachel noch nicht bekannt gegeben, hat jedoch erklärt, dass die Komponenten in einer passiven Konfiguration mit einigen GHz laufen können (eine Aussage, die die Existenz einer aktiven Version der Zwischenschicht impliziert, die Intel bereits entwickelt). ).Somit verlangt Foveros vom Designer keine Kompromisse bei Bandbreiten- oder Latenzbeschränkungen.
Intel erwartet außerdem, dass sich das Design sowohl hinsichtlich der Leistung als auch der Kosten gut skalieren lässt, sodass spezielle Designs für andere Marktsegmente oder Varianten der Hochleistungsversion angeboten werden können.
Die Kosten moderner Knoten pro Transistor steigen exponentiell, da die Siliziumchip-Prozesse an ihre Grenzen stoßen.Und die Entwicklung neuer IP-Module (z. B. I/O-Schnittstellen) für kleinere Knoten bringt keine große Kapitalrendite.Daher kann die Wiederverwendung unkritischer Kacheln/Chiplets auf „ausreichend guten“ vorhandenen Knoten Zeit, Kosten und Entwicklungsressourcen sparen, ganz zu schweigen von der Vereinfachung des Testprozesses.
Bei einzelnen Chips muss Intel nacheinander verschiedene Chipelemente wie Speicher oder PCIe-Schnittstellen testen, was ein zeitaufwändiger Prozess sein kann.Im Gegensatz dazu können Chiphersteller auch kleine Chips gleichzeitig testen, um Zeit zu sparen.Abdeckungen bieten auch beim Design von Chips für bestimmte TDP-Bereiche einen Vorteil, da Designer verschiedene kleine Chips an ihre Designanforderungen anpassen können.
Die meisten dieser Punkte kommen mir bekannt vor, und es handelt sich bei allen um die gleichen Faktoren, die AMD 2017 auf den Chipsatz-Weg geführt haben. AMD war nicht der erste, der Chipsatz-basierte Designs verwendete, aber es war der erste große Hersteller, der diese Designphilosophie nutzte moderne Chips in Massenproduktion herzustellen, wozu Intel offenbar etwas spät gekommen ist.Allerdings ist die von Intel vorgeschlagene 3D-Packaging-Technologie weitaus komplexer als das auf organischen Zwischenschichten basierende Design von AMD, das sowohl Vor- als auch Nachteile hat.
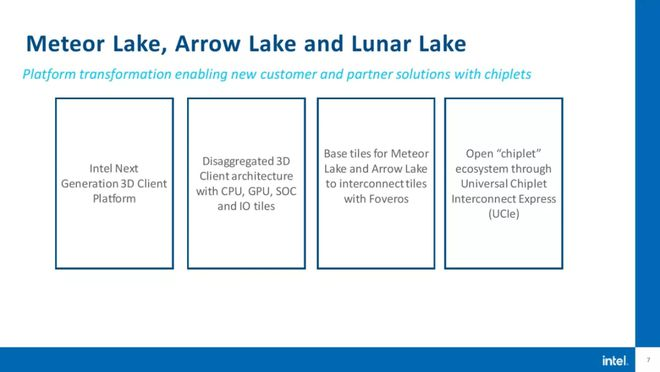
Der Unterschied wird sich letztendlich in den fertigen Chips widerspiegeln, wobei Intel sagt, dass der neue 3D-Stacked-Chip Meteor Lake voraussichtlich im Jahr 2023 verfügbar sein wird, Arrow Lake und Lunar Lake im Jahr 2024.
Intel sagte außerdem, dass der Supercomputerchip Ponte Vecchio, der über mehr als 100 Milliarden Transistoren verfügen wird, voraussichtlich das Herzstück von Aurora sein wird, dem schnellsten Supercomputer der Welt.
-

XC7K325T-1FBG676I 676-FCBGA (27×27) integriert...
-

IRLML6402TRPBF Neue und originale integrierte Schaltung...
-

IPD135N08N3G Brandneuer integrierter Schaltkreis mit ...
-

Brandneuer Original-MOSFET TO-220-3 IRFB4321PBF
-

Integrierter Schaltkreis, neue und originale elektronische...
-

JXSQ Neue und originale IC-Chips REG BUCK ADJ 3,5...